- Теоретические основы буфера
- Реализация цикличной очереди
- Стандартный вариант использования
- Спецификация функциональных требований
- Создание буфера в C/C ++
- Реализация библиотечных функций
- Добавление и удаление данных
- Интерфейс шаблонного класса
- Драйвер UART STM32
- Репозиторий данных UART
- Реализация в ARDUINO
- Высокопроизводительные операции CAS
Кольцевой буфер также известен, как очередь или циклический буфер и является распространенной формой очереди. Это популярный, легко реализуемый стандарт, и, хотя он представлен в виде круга, в базовом коде он является линейным. Кольцевая очередь существует как массив фиксированной длины с двумя указателями: один представляет начало очереди, а другой - хвост. Недостатком метода является его фиксированный размер. Для очередей, где элементы должны быть добавлены и удалены в середине, а не только в начале и конце буфера, реализация в виде связанного списка является предпочтительным подходом.
Теоретические основы буфера
 Вам будет интересно:Полезные apk-приложения для "Андроида": обзор лучших программ
Вам будет интересно:Полезные apk-приложения для "Андроида": обзор лучших программ
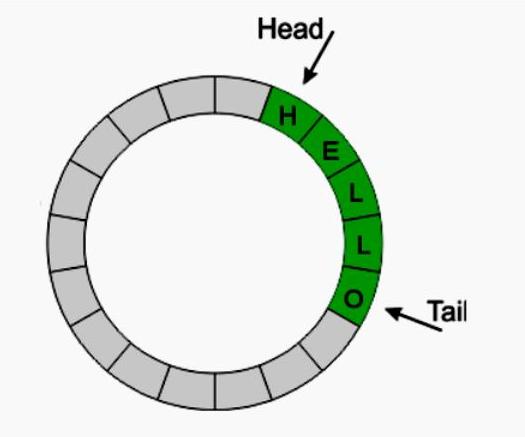
Пользователю легче сделать выбор эффективной структуры массивов после понимания основополагающей теории. Циклический буфер - структура данных, где массив обрабатывается и визуализируется в виде циклов, то есть индексы возвращаются к 0 после достижения длины массива. Это делается с помощью двух указателей на массив: «head» и «tail». Когда данные добавляются в буфер, указатель заголовка перемещается вверх. Точно так же, когда они удаляются, то хвост тоже перемещается вверх. Определение головы, хвоста, направления их движения, места записи и чтения зависят от реализации схемы.
Круговые буферы чрезмерно эффективно используются для решения проблем потребителя. То есть один поток выполнения отвечает за производство данных, а другой - за потребление. Во встроенных устройствах с очень низким и средним уровнем производитель представлен в формате ISR (информация, полученная от датчиков), а потребитель - в виде основного цикла событий.
 Вам будет интересно:Оптическое распознавание символов (optical character recognition, OCR). Программы для оптического распознавания символов: ABBYY FineReader, CuneiForm
Вам будет интересно:Оптическое распознавание символов (optical character recognition, OCR). Программы для оптического распознавания символов: ABBYY FineReader, CuneiForm
Особенностью циклических буферов является то, что они реализуются без необходимости блокировок в среде одного производителя и одного потребителя. Это делает их идеальной информационной структурой для встроенных программ. Следующее отличие - не существует точного способа дифференцирования заполненного сектора от пустого. Это потому, что в обоих случаях голова сливается с хвостом. Есть много способов и обходных путей, чтобы справиться с этим, но большинство из них вносят большую спутанность и затрудняют читабельность.
Еще один вопрос, который возникает в отношении циклического буфера. Нужно ли сбрасывать новые данные или перезаписывать существующие, когда он заполнен? Специалисты утверждают, что нет явного преимущества одного над другим, а его реализация зависит от конкретной ситуации. Если последние имеют больше значимости для приложения, используют метод перезаписи. С другой стороны, если они обрабатываются в режиме «первым пришел - первым обслужен», то отбрасывают новые, когда кольцевой буфер заполнен.
Реализация цикличной очереди
Приступая к реализации, определяют типы данных, а затем методы: core, push и pop. В процедурах «push» и «pop» вычисляют «следующие» точки смещения для местоположения, в котором будет происходить текущая запись и чтение. Если следующее местоположение указывает на хвост, значит, буфер заполнен и данные больше не записываются. Точно так же, когда «head» равен «tail», он пуст и из него ничего не читается.
 Вам будет интересно:Замена Microsoft Office: альтернативные системы, рейтинг лучших, рекомендации и отзывы
Вам будет интересно:Замена Microsoft Office: альтернативные системы, рейтинг лучших, рекомендации и отзывы

Стандартный вариант использования
Вспомогательная процедура вызывается процессом приложения для извлечения данных из кольцевого буфера Java. Она должен быть включена в критические разделы, если считывают контейнер более одного потока. Хвост перемещается к следующему смещению до того, как информация будет прочитана, поскольку каждый блок составляет один байт и резервируется аналогичное количество в буфере, когда объем полностью загружен. Но в более продвинутых реализациях циклического накопителя единичные разделы необязательно должны быть одинакового размера. В таких случаях стараются сохранить даже последний байт, добавив больше проверок и границ.
В таких схемах, если хвост передвигается перед чтением, информация, которая должна быть прочитана, потенциально может быть перезаписана вновь выдвинутыми данными. В общем случае рекомендуется сначала читать, а затем перемещать хвостовой указатель. Вначале определяют длину буфера, а затем создают экземпляр «circ_bbuf_t» и назначают указатель «maxlen». При этом контейнер должен быть глобальным или находиться в стеке. Так, например, если нужен кольцевой буфер длиной 32 байта, выполняют в приложении следующее (см. рисунок ниже).
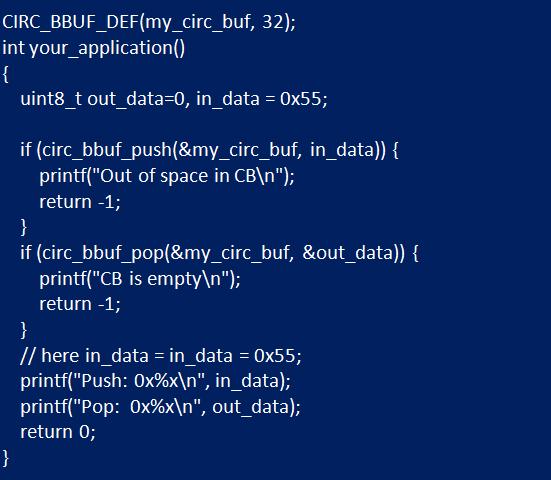
Спецификация функциональных требований
Тип данных «ring_t» будет типом данных, который содержит указатель на буфер, размер его, индекс заголовка и хвоста, счетчик данных.
Функция инициализации «ring_init ()» инициализирует буфер на основе получения указателя на структуру контейнера, созданного вызывающей функцией, имеющей предопределенный размер.
Функция добавления звонка «ring_add ()» добавит байт в следующий доступный пробел в буфере.
Функция удаления кольца «ring_remove ()» удалит байт из самого старого допустимого места в контейнере.
Ring peek в функции «ring_peek ()» будет считывать число байтов «uint8_t 'count'» из кольцевого буфера в новый, предоставленный в качестве параметра, без удаления каких-либо значений, считанных из контейнера. Он вернет количество фактически прочитанных байтов.
Функция очистки кольца «ring_clear ()» установит «Tail» равным «Head» и загрузит «0» во все позиции буфера.
Создание буфера в C/C ++
Из-за ограниченности ресурсов встроенных систем структуры данных с циклическим буфером можно найти в большинстве проектов фиксированного размера, которые работают так, как если бы память по своей природе была непрерывной и циклической. Данные не нужно переставлять, поскольку память генерируется и используется, а корректируются указатели головы/хвоста. Во время создания циклической буферной библиотеки нужно, чтобы пользователи работали с библиотечными API, а не изменяли структуру напрямую. Поэтому используют инкапсуляцию кольцевого буфера на "Си". Таким образом разработчик сохранит библиотечную реализацию, изменяя ее по мере необходимости, не требуя, чтобы конечные пользователи также обновляли ее.
 Вам будет интересно:Формат кадра Ethernet: типы, первоначальная версия и внутренняя модификация
Вам будет интересно:Формат кадра Ethernet: типы, первоначальная версия и внутренняя модификация
Пользователи не могут работать с «circular_but_t» указателем, создается тип дескриптора, который можно использовать вместо него. Это избавит от необходимости приводить указатель в реализации функции «.typedefcbuf_handle_t». Разработчикам нужно собрать API для библиотеки. Они взаимодействуют с библиотекой кольцевого буфера «C», используя непрозрачный тип дескриптора, который создается во время инициализации. Обычно выбирают «uint8_t» в качестве базового типа данных. Но можно использовать любой конкретный тип, проявляя осторожность, чтобы правильно обрабатывать базовый буфер и количество байтов. Пользователи взаимодействуют с контейнером, выполняя обязательные процедуры:
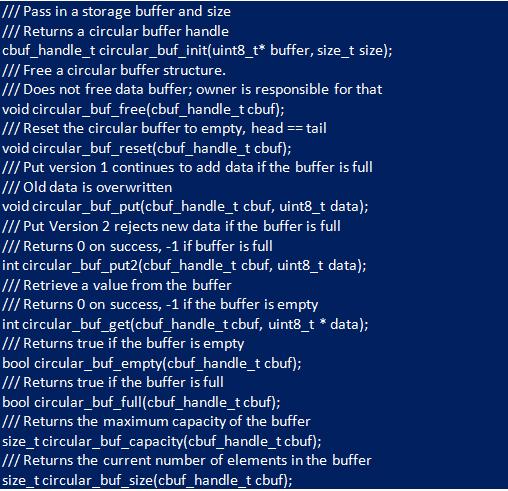
И «полный», и «пустой» случаи выглядят одинаково: "head" и "tail", указатели равны. Существует два подхода, различающие полный и пустой:
Реализация библиотечных функций
Для создания кругового контейнера используют его структуру для управления состоянием. Чтобы сохранить инкапсуляцию, структура определяется внутри библиотечного «.c» файла, а не в заголовке. При установке нужно будет отслеживать:
Теперь, когда контейнер спроектирован, реализуют библиотечные функции. Каждый из API требует инициализированного дескриптора буфера. Вместо того чтобы засорять код условными утверждениями, применяют утверждения для обеспечения выполнения требований API в стиле.

Реализация не будет являться поточно-ориентированной, если в базовую библиотеку циклических хранилищ не были добавлены блокировки. Для инициализации контейнера у API есть клиенты, которые предоставляют базовый размер буфера, поэтому создают его на стороне библиотеки, например, для простоты «malloc». Системы, которые не могут использовать динамическую память, должны изменить «init» функцию, чтобы использовать другой метод, например, такой как выделение из статического пула контейнеров.
Другой подход заключается в нарушении инкапсуляции, что позволяет пользователям статически объявлять структуры контейнеров. В этом случае «circular_buf_init» необходимо обновить, чтобы взять указатель или «init», создать структуру стека и вернуть ее. Однако, поскольку инкапсуляция нарушена, пользователи смогут изменять ее без библиотечных процедур. После того как создан контейнер, заполняют значения и вызывают "reset". Прежде чем вернуться из «init», система гарантирует, что контейнер создан в пустом состоянии.

Добавление и удаление данных
Добавление и удаление данных из буфера требует манипуляций с «head»- и «tail»-указателями. При добавлении в контейнер вставляют новое значение в текущем "head"-месте и продвигают его. Когда удаляют, получают значение текущего "tail"-указателя и продвигают «tail». Если нужно продвинуть "tail"-указатель, а также «head», необходимо проверить, вызывает ли вставка значения "full". Когда буфер уже заполнен, продвигают «tail» на шаг впереди «head».
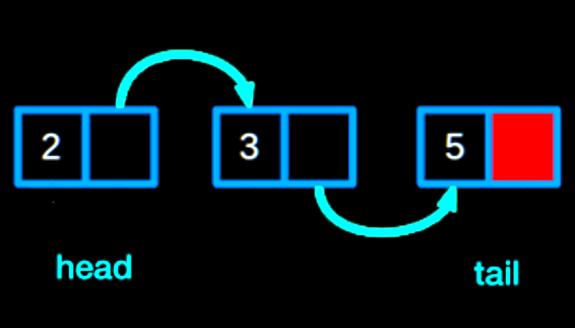
После того как указатель был продвинут, заполняют "full"-флаг, проверяя равенство "head == tail". Модульное использование оператора приведет к тому, что «head» и «tail» сбросят значения в "0", когда будет достигнут максимальный размер. Это гарантирует, что «head» и «tail» всегда будут действительными индексами базового контейнера данных: "static void advance_pointer (cbuf_handle_t cbuf)". Можно создать аналогичную вспомогательную функцию, которая вызывается при удалении значения из буфера.
Интерфейс шаблонного класса
Для того чтобы реализация C ++ поддерживала любые типы данных, выполняют шаблон:
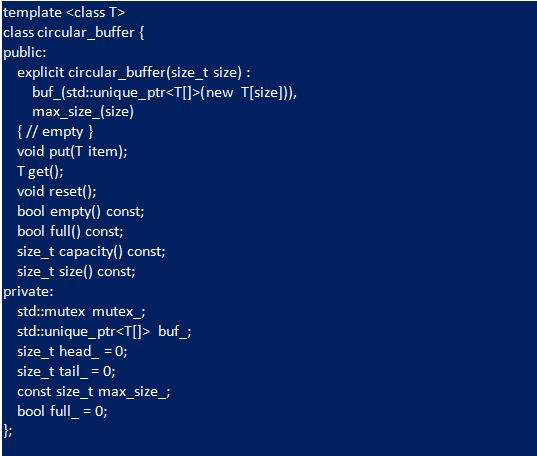
В этом примере буфер C ++ имитирует большую часть логики реализации C, но в результате получается гораздо более чистый и многократно используемый дизайн. Кроме того, контейнер C ++ использует "std::mutex" для обеспечения поточно-ориентированной реализации. При создании класса выделяют данные для основного буфера и устанавливают его размер. Это устраняет накладные расходы, требуемые с реализацией C. В отличие от нее, конструктор C ++ не вызывает "reset", поскольку указывают начальные значения для переменных-членов, круговой контейнер запускается в правильном состоянии. Поведение сброса возвращает буфер в пустое состояние. В реализации циклического контейнера C ++ «size» и «capacity» сообщает количество элементов в очереди, а не размер в байтах.
Драйвер UART STM32
После запуска буфера, он должен быть интегрирован в драйвер UART. Сначала как глобальный элемент в файле, поэтому необходимо объявить:
- "descriptor_rbd" и буферную память "_rbmem: static rbd_t _rbd";
- "static char _rbmem [8]".
Поскольку это драйвер UART, где каждый символ должен быть 8-разрядным, создание массива символов допустимо. Если используется 9- или 10-битный режим, то каждый элемент должен быть "uint16_t". Контейнер рассчитывается таким образом, чтобы избежать потери данных.
Часто модули очередей содержат статистическую информацию, позволяющую отслеживать максимальное использование. В функции инициализации «uart_init» буфер должен быть инициализирован путем вызова «ring_buffer_init» и передачи структуры атрибутов с каждым членом, которому назначены обсуждаемые значения. Если он успешно инициализируется, модуль UART выводится из сброса, прерывание приема разрешено в IFG2.
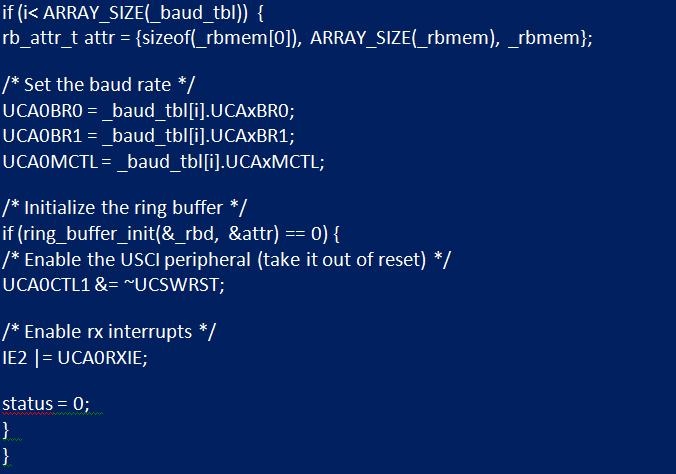
Вторая функция, которая должна быть изменена, - это "uart_getchar". Считывание полученного символа из периферийного устройства UART заменяется чтением из очереди. Если очередь пуста, функция должна вернуть -1. Далее нужно внедрить UART для получения ISR. Открывают файл заголовка "msp430g2553.h", прокручивают вниз до секции векторов прерываний, где находят вектор с именем USCIAB0RX. Именование подразумевает, что это оно используется модулями USCI A0 и B0. Статус прерывания приема USCI A0 можно прочитать из IFG2. Если он установлен, флаг должен быть очищен, а данные в приемном отсеке помещены в буфер с помощью «ring_buffer_put».
Репозиторий данных UART
 Вам будет интересно:Стандарты информационной безопасности международные и национальные, технологии
Вам будет интересно:Стандарты информационной безопасности международные и национальные, технологии
Этот репозиторий дает информацию о том, как считывать данные по UART с использованием DMA, когда количество байтов для приема заранее неизвестно. В семействе микроконтроллеров кольцевой буфер STM32 может работать в разных режимах:
Реализация в ARDUINO
Кольцевой буфер Arduino относится как к проектированию плат, так и к среде программирования, которая используется для работы. Ядром Arduino является микроконтроллер серии Atmel AVR. Именно AVR выполняет большую часть работы, и во многих отношениях плата Arduino вокруг AVR представляет функциональность - легко подключаемые контакты, USB-последовательный интерфейс для программирования и связи.
Многие из обычных плат Arduino в настоящее время используют кольцевой буфер c ATmega 328, более старые платы использовали ATmega168 и ATmega8. Платы вроде Mega выбирают более сложные варианты, такие как 1280 и аналогичные. Чем быстрее Due и Zero, тем лучше используйте ARM. Существует около десятка различных плат Arduino с именами. Они могут иметь разное количество флеш-памяти, ОЗУ и порты ввода-вывода с кольцевым буфером AVR.
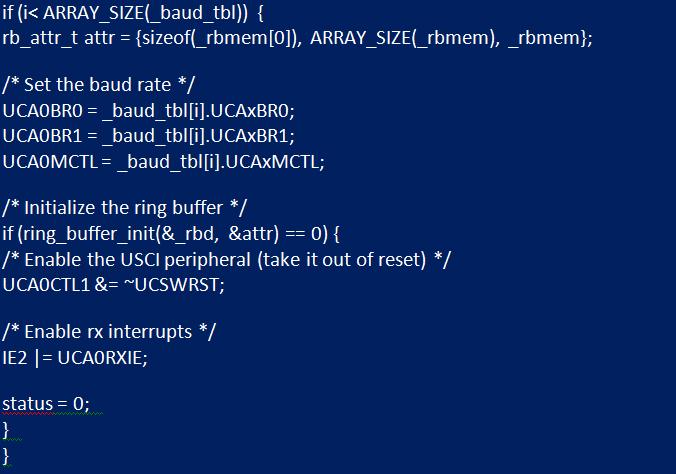
Переменную «roundBufferIndex» используют для хранения текущей позиции, а при добавлении в буфер произойдет ограничение массива.
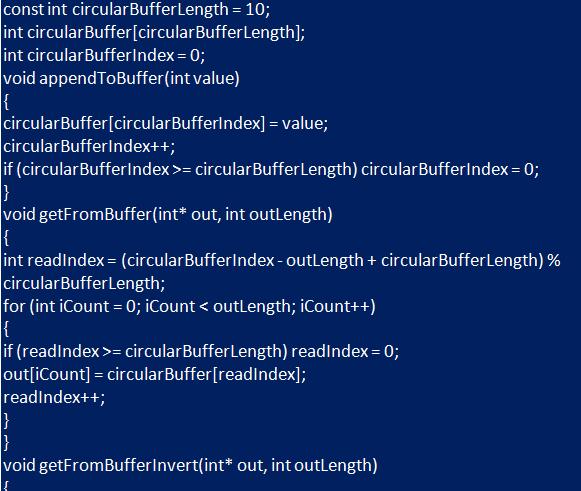
Это результаты выполнения кода. Числа хранятся в буфере, и, когда они заполнены, они начинают перезаписываться. Таким образом можно получить последние N чисел.
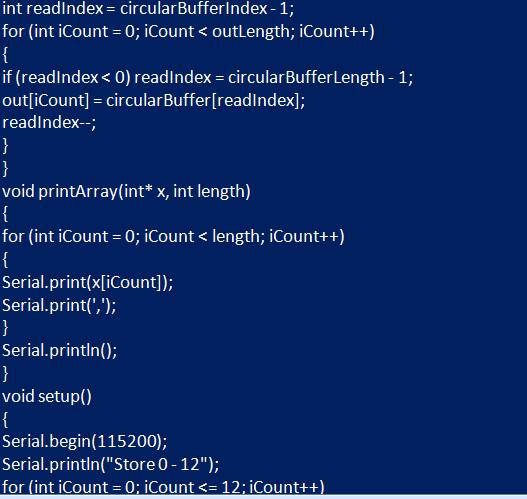
В предыдущем примере использован индекс для доступа к текущей позиции буфера, потому что он достаточен для объяснения операции. Но в общем, нормальным является то, что используется указатель. Это модифицированный код для использования указателя вместо индекса. По сути, операция такая же, как и предыдущая, а полученные результаты аналогичны.
Высокопроизводительные операции CAS
Disruptor - это высокопроизводительная библиотека для передачи сообщений между потоками, разработанная и открытая несколько лет назад компанией LMAX Exchange. Они создали это программное обеспечение для обработки огромного трафика (более 6 миллионов TPS) в своей розничной финансовой торговой платформе. В 2010 году они удивили всех тем, насколько быстрой может быть их система, выполнив всю бизнес-логику в одном потоке. Хотя один поток был важной концепцией в их решении, Disruptor работает в многопоточной среде и основан на кольцевом буфере - поток, в котором устаревшие данные больше не нужны, потому что поступают более свежие и более актуальные.
В этом случае сработает либо возврат ложного логического значения, либо блокировка. Если ни одно из этих решений не удовлетворяет пользователей, можно реализовать буфер с изменяющемся размером, но только тогда, когда он заполняется, а не только тогда, когда производитель достигает конца массива. Изменение размера потребует перемещения всех элементов во вновь выделенный больший массив, если он используется в качестве базовой структуры данных, что, конечно, является дорогостоящей операцией. Есть много других вещей, которые делают Disruptor быстрым, например потребление сообщений в пакетном режиме.
Кольцевой буфер "qtserialport" (последовательный порт) наследуется от QIODevice, может быть использован для получения различных последовательной информации и включает в себя все из доступных последовательных устройств. Последовательный порт всегда открыт в монопольном доступе, это означает, что другие процессы или потоки не могут получить доступ к открытому последовательному порту.
Кольцевые буферы очень полезны в программировании на "Си", например, можно оценить поток байтов, поступающих через UART.