Сжатие является частным случаем кодирования, основной характеристикой которого является то, что результирующий код меньше исходного. Процесс основан на поиске повторений в информационных рядах и последующем сохранении только одного рядом с количеством повторений. Таким образом, например, если последовательность появляется в файле, как «AAAAAA», занимая 6 байтов, он будет сохранен, как «6A», который занимает только 2 байта, в алгоритме сжатия RLE.
История возникновения процесса
 Вам будет интересно:Что такое в "Фотошопе" смарт-объект? Его назначение
Вам будет интересно:Что такое в "Фотошопе" смарт-объект? Его назначение
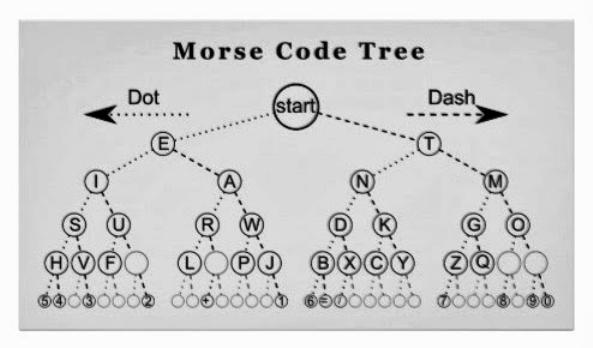
Азбука Морзе, изобретенная в 1838 году - первый известный случай сжатия данных. Позже, когда в 1949 году мейнфрейм-компьютеры начали завоевывать популярность, Клод Шеннон и Роберт Фано изобрели кодирование, названного в честь авторов - Шеннона-Фано. Это шифрование присваивает коды символам в массиве данных по теории вероятности.
Только в 1970-х с появлением интернета и онлайн-хранилищ, были реализованы полноценные алгоритмы сжатия. Коды Хаффмана динамически генерировались на базе входной информации. Ключевое различие между кодированием Шеннона-Фано и кодированием Хаффмана состоит в том, что в первом дерево вероятности строилось снизу вверх, создавая неоптимальный результат, а во втором - сверху вниз.
В 1977 году, Авраам Лемпель и Джейкоб Зив издали свой инновационный метод LZ77, использующий более модернизированный словарь. В 1978 году, та же команда авторов, издала усовершенствованный алгоритм сжатия LZ78. Который использует новый словарь, анализирующий входные данные и генерирующий статический словарь, а не динамический, как у 77 версии.
Формы исполнения компрессии
Компрессия выполняется программой, которая использует формулу или алгоритм, определяющих, как уменьшить размер данных. Например, представить строку битов с меньшей строкой 0 и 1, используя словарь для преобразований или формулу.
Сжатие может быть простым. Таким, например, как удаление всех ненужных символов, вставки одного повторяющегося кода для указания строки повтора и замена битовой строки меньшего размера. Алгоритм сжатия файлов способен уменьшить текстовый файл до 50% или значительно больше.
Для передачи процесс выполняют в блоке передачи, включая данные заголовка. Когда информация отправляется или принимается через интернет, заархивированные по отдельности или вместе с другими большими файлами, могут передаваться в ZIP, GZIP или другом "уменьшенном" формате.
 Вам будет интересно:Единицы количества информации: бит, байт, килобайт, мегабайт, гигабайт, терабайт
Вам будет интересно:Единицы количества информации: бит, байт, килобайт, мегабайт, гигабайт, терабайт
Преимущество алгоритмов сжатия:
Применяют методы двух видов - алгоритмы сжатия без потерь и с потерями. Первый позволяет восстановить файл в исходное состояние без утраты одного бита информации при несжатом файле. Второй - это типичный подход к исполняемым файлам, текстовым и электронным таблицам, где потеря слов или чисел приведет к изменению информации.
Сжатие с потерями навсегда удаляет биты данных, которые являются избыточными, неважными или незаметными. Оно полезно с графикой, аудио, видео и изображениями, где удаление некоторых битов практически не оказывает заметного влияния на представление контента.
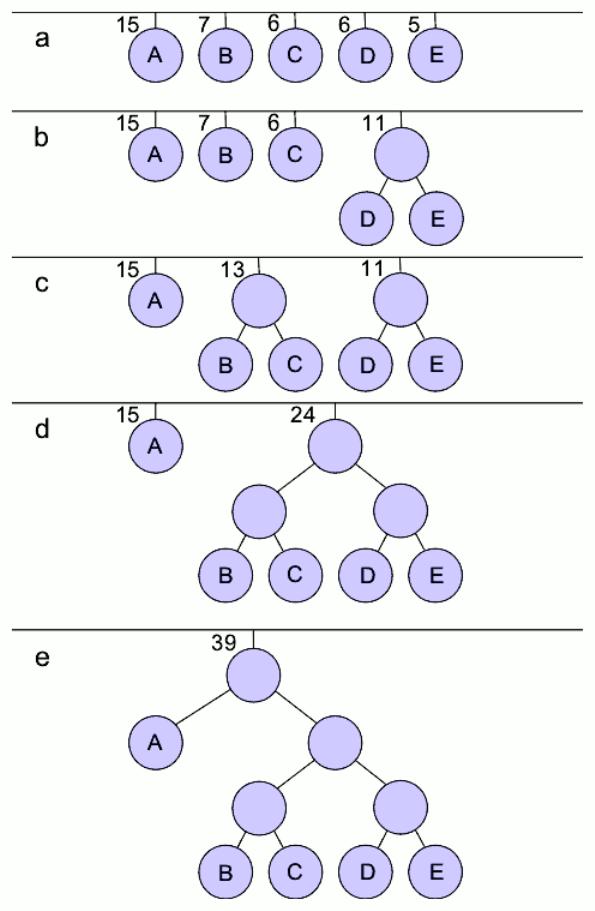
Алгоритм сжатия Хаффмана
Этот процесс, который можно использовать для "уменьшения" или шифрования.
Он основан на назначении кодов различной длины битов соответствующему каждому повторяющемуся символу, чем больше таких повторов, тем выше степень сжатия. Чтобы восстановить исходный файл, необходимо знать назначенный код и его длину в битах. Аналогичным образом, используют программу для шифрования файлов.
Порядок создания алгоритмы сжатия данных:
 Вам будет интересно:Грамотная разметка диска для Linux
Вам будет интересно:Грамотная разметка диска для Linux

Как видно, корневой узел дерева создан, далее назначаются коды.

И осталось только упаковать биты в группы по восемь, то есть в байты:
01110010
11010101
11111011
00010010
11010101
11110111
10111001
10000000
0x72
0xd5
0xFB
0x12
0xd5
0xF7
0xB9
0x80
Всего восемь байтов, а исходный текст был 23.
Демонстрация библиотеки LZ77
Алгоритм LZ77 рассмотрим на примере текста«howtogeek». Если повторить его три раза, то он изменит его следующим образом.

Затем, когда он захочет прочитать текст обратно, он заменит каждый экземпляр (h) на «howtogeek», возвращаясь к исходной фразе. Это демонстрирует алгоритм сжатия данных без потерь, поскольку данные, которые вводятся, совпадают с получаемыми.
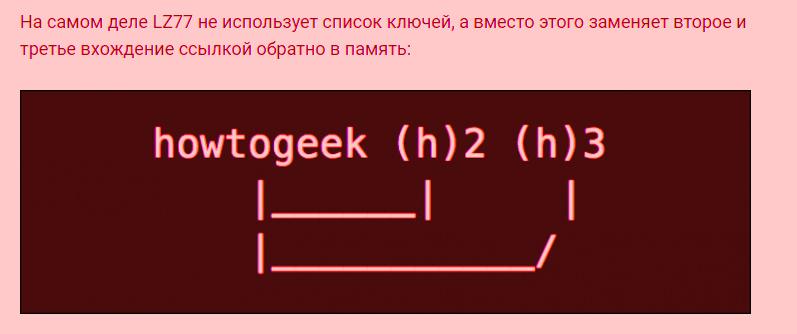
Это идеальный пример, когда большая часть текста сжимается с помощью нескольких символов. Например, слово «это» будет сжато, даже если оно встречается в таких словах, как «этом», «их» и «этого». С повторяющимися словами можно получить огромные коэффициенты сжатия. Например, текст со словом «howtogeek», повторенным 100 раз имеет размер три килобайта, при компрессии займет всего 158 байт, то есть с 95% "уменьшением".
Это, конечно, довольно экстремальный пример, но наглядно демонстрирует свойства алгоритмов сжатия. В общей практике он составляет 30-40% с текстовым форматом ZIP. Алгоритм LZ77, применяется ко всем двоичным данным, а не только к тексту, хотя последний легче сжать из-за повторяющихся слов.
Дискретное косинусное преобразование изображений
Сжатие видео и аудио работает совсем по-другому. В отличие от текста, где выполняют алгоритмы сжатия без потерь, и данные не будут потеряны, с изображениями выполняют "уменьшение" с потерями, и чем больше %, тем больше потерь. Это приводит к тем ужасно выглядящим JPEG-файлам, которые люди загружали, обменивали и делали скриншоты по несколько раз.
Большинство картинок, фото и прочего хранят список чисел, каждый из которых представляет один пиксель. JPEG сохраняет их, используя алгоритм сжатия изображений, называемым дискретным косинусным преобразованием. Оно представляет собой совокупность синусоидальных волн, складывающихся вместе с различной интенсивностью.
Этот метод использует 64 различных уравнения, затем кодировку Хаффмана, чтобы еще больше уменьшить размер файла. Подобный алгоритм сжатия изображений дает безумно высокую степень сжатия, и уменьшает его от нескольких мегабайт до нескольких килобайт, в зависимости от требуемого качества. Большинство фото сжимаются, чтобы сэкономить время загрузки, особенно для мобильных пользователей с плохой передачей данных.
Видео работает немного иначе, чем изображения. Обычно алгоритмы сжатия графической информации используют тем, что называется «межкадровым сжатием», которое вычисляет изменения между каждым кадром и сохраняет их. Так, например, если есть относительно неподвижный снимок, который занимает несколько секунд в видео, он будет "уменьшен" в один. Межкадровое сжатие обеспечивает цифровое телевидение и веб-видео. Без него видео весило бы сотнями гигабайт, что больше среднего размера жесткого диска в 2005 году.
Сжатие аудио работает очень похоже на сжатие текста и изображений. Если JPEG удаляет детали из изображения, которое не видны человеческим глазом, сжатие звука делает, то же самое для звуков. MP3 использует битрейт, в диапазоне от нижнего уровня 48 и 96 кбит/с (нижний предел) до 128 и 240 кбит/с (довольно хороший) до 320 кбит/с (высококачественный звук), и услышать разницу можно только с исключительно хорошими наушниками. Существуют кодеки сжатия без потерь для звука, основным из которых является FLAC и использует кодирование LZ77 для передачи звука без потерь.
Форматы "уменьшения" текста
Диапазон библиотек для текста в основном состоит из алгоритма сжатия данных без потерь, за исключением крайних случаев для данных с плавающей запятой. Большинство компрессорных кодеков включают "уменьшение" LZ77, Хаффмана и Арифметическое кодирование. Они применяемых после других инструментов, чтобы выжать еще несколько процентных точек сжатия.

Прогоны значений кодируются, как символ, за которым следует длина прогона. Можно правильно восстановить оригинальный поток. Если длина серии<= 2 символа, имеет смысл просто оставить их без изменения, например, как в конце потока с «bb».
В некоторых редких случаях получают дополнительную экономию, применяя преобразование с алгоритмами сжатия с потерями к частям контента перед применением безпотерного метода. Поскольку в этих преобразованиях файлы не подлежат восстановлению до исходного состояния, эти "процессы" зарезервированы для текстовых документов. Которые не пострадают от потери информации, например, усечение цифр с плавающей запятой только до двух значащих десятичных разрядов.

Сегодня большинство систем сжатия текста работают, объединяя различные преобразования данных для достижения максимального результата. Смысл каждого этапа системы состоит в том, чтобы выполнить преобразовать таким образом, чтобы следующий этап мог продолжить эффективное сжатие. Суммирование этих этапов дает небольшой файл, который можно восстановить без потерь. Существует буквально сотни форматов и систем сжатия, каждый из которых имеет свои плюсы и минусы по отношению к разным типам данных.
Схемы HTTP: DEFLATE и GZIP
Сегодня в интернете используют два широко используемых алгоритмов сжатия текста HTTP: DEFLATE и GZIP.
DEFLATE - обычно объединяющий данные, с применением LZ77, кодирования Хаффмана. GZIP – файла использует DEFLATE внутри, наряду с некоторыми интересными блокировками, эвристикой фильтрации, заголовком и контрольной суммой. В целом, дополнительная блокировка и эвристика, использующие GZIP, дают качественные коэффициенты сжатия, чем просто один DEFLATE.
Протоколы данных следующего поколения - SPDY и HTTP2.0, поддерживают сжатие заголовков с помощью GZIP, поэтому большая часть веб-стека будет использовать его и в будущем.
Большинство разработчиков просто загружают несжатый контент и полагаются на веб-сервер для "уменьшения" данных на лету. Это дает отличные результаты и простой в использовании алгоритм сжатия графических изображений. По умолчанию на многих серверах установлен GZIP с уровнем 6, наибольший уровень которого равен 9. Это сделано преднамеренно, что позволяет серверам компрессировать данные быстрее за счет большего выходного файла.
Форматы BZIP2 и LZMA, создающие более компактные формы чем GZIP, которые при этом распаковываются быстрее.
LZMA можно считать дальним родственником GZIP. Оба они начинаются с популярного словаря LZ, за которым следует система статистического кодирования. Однако улучшенная LZMA-возможность компрессировать файлы малого размера заключается в его «продвинутых алгоритмах сопоставления и окон LZ.
Предварительная обработка документа

Для качественного сжатия выполняют двухэтапный процесс:
- этап минимизации;
- этап без потерь.
Минификация - это сокращение размера данных таким образом, чтобы они могли использоваться без обработки, стирая в файле много ненужного, не изменяя их синтаксически. Так, безопасно удалить большую часть пробелов из Jscript, снижая размер без изменений синтаксиса. Минификация выполняется во время процесса сборки. Либо как ручной шаг, либо как часть автоматизированной цепочки сборки.
Есть много программ, которые выполняют основные алгоритмы сжатия, среди них:
Минификаторы CSS

Существует много минификаторов CSS. Некоторые из доступных вариантов включают:
- онлайн CSS Minifier;
- freeformatter.com/css-minifier;
- cleancss.com/css-minify;
- cnvyr.io;
- minifier.org;
- css-minifier.com.
Основное различие между этими инструментами зависит от того, насколько глубоки их процессы минификации. Так, упрощенная оптимизация фильтрует текст, чтобы убрать ненужные пробелы и массивы. Развитая оптимизация предусматривает замену «AntiqueWhite» на « # FAEBD7 », поскольку шестнадцатеричная форма в файле короче, и принудительное использование символа нижнего GZIP-регистра.
Более агрессивные способы CSS экономят место, но могут нарушить требования CSS. Таким образом, большинство из них не имеют возможности быть автоматизированными, и разработчики делают выбор между размером или степенью риска.
На самом деле, есть новая тенденция создания других версий из языков CSS, чтобы более эффективно помочь автору кода в качестве дополнительного преимущества, позволяющая компилятору производить меньший код CSS.
Плюсы и минусы сжатия

Основными преимуществами сжатия являются сокращение аппаратных средств хранения, времени передачи данных и пропускной способности связи.
Такой файл требует меньшего объема памяти, а использование метода приводит к снижению затрат на дисковые или твердотельные накопители. Он требует меньше времени для передачи при низкой пропускной способности сети.
Основным недостатком компрессии является влияние на производительность в результате использования ресурсов ЦП и памяти для процесса и, последующей распаковки.
Многие производители разработали системы, чтобы попытаться минимизировать влияние ресурсоемких вычислений, связанных со сжатием. Если оно выполняется до того как данные будут записаны на диск, система может разгрузить процесс, чтобы сохранить системные ресурсы. Например, IBM использует отдельную карту аппаратного ускорения для обработки сжатия в некоторых корпоративных системах хранения.
Если данные сжимаются после их записи на диск или после обработки, оно выполняться в фоновом режиме, чтобы уменьшить влияние на производительность машины. Хотя сжатие после обработки уменьшает время отклика для каждого ввода и вывода (I / O), оно все еще потребляет память и циклы процессора и влиять на количество операций, которые обрабатывает система хранения. Кроме того, поскольку данные изначально должны быть записаны на диск или флэш-накопители в несжатом виде, экономия физической памяти не так велика, как при встроенном "уменьшении".
Будущее никогда не определено, но исходя из текущих тенденций, можно сделать некоторые прогнозы относительно того, что может произойти с технологией сжатия данных. Алгоритмы смешивания контекста, такие как PAQ и его варианты, начали приобретать популярность, и они имеют тенденцию достигать самых высоких коэффициентов "уменьшения". Хотя обычно они медленные.
С экспоненциальным увеличением аппаратной скорости в соответствии с законом Мура, процессы смешивания контекста, вероятно, будут процветать. Так как затраты на скорость преодолеваются за счет быстрого оборудования из-за высокой степени сжатия. Алгоритм, который PAQ стремился улучшить, называется "Прогнозирование путей частичного сопоставления". Или PPM.
Наконец, цепной алгоритм Лемпеля-Зива-Маркова (LZMA) неизменно демонстрирует превосходный компромисс между скоростью и высокой степенью сжатия и, вероятно, создаст больше новых вариантов в будущем. Он будет лидировать, поскольку уже принят во многих конкурирующих форматах сжатия, например, в программе 7-Zip.
Другим потенциальным развитием является использование компрессии с помощью перечисления подстрок (CSE), которая представляет собой перспективную технологию и пока не имеет много программных реализаций.