- Синтаксис конструкции LIMIT
- Большие значения limit "O, R"
- Выборка одной уникальной записи
- Реляционные отношения в MySQL
- Большие объемы и стандартный кэш
- Табличная постраничная организация
- Собственный кэш и понятие актуальности
- Сортировки и другие оптовые операции
- Естественное восприятие информации
- Информационные объекты и естественные ассоциации
Выбор конкретного количества записей из большого набора - идея хорошая, но когда набор действительно большой, возникает эффект деградации идеи. Выбор нескольких записей с некоторой позиции создаёт реальное падение производительности: перед достижением цели MySQL просматривает другие записи, затрачивая на это время.

Формально MySQL limit может работать с начала таблицы или с её конца. Выборка может определять конкретное количество записей и начинаться с заданной позиции. Всегда может возникнуть случай, то есть наступление худшей ситуации возможно. Обычно общий поток клиентов обуславливает общий статистический режим работы, но предусмотреть разные ситуации необходимо, это серьёзное решение в пользу сайта.
Синтаксис конструкции LIMIT
 Вам будет интересно:Группировка записей MySQL: group by
Вам будет интересно:Группировка записей MySQL: group by
В официальных источниках MySQL limit syntax обозначен, как представлено на изображении ниже, в контексте запросов select и delete.
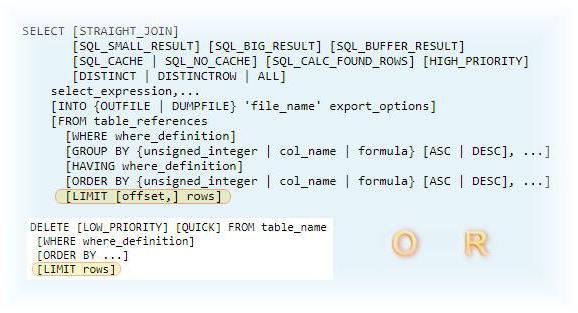
Запрос на выборку (select) предусматривает два числа: смещение "O" и количество "R", запрос на удаление (delete) записывается одним числом - количеством удаляемых записей "R".
Большие значения limit "O, R"
 Вам будет интересно:Программирование на Python: список
Вам будет интересно:Программирование на Python: список
MySQL limit: синтаксис допускает выборку значений по любой схеме. Базовые условия: "O" - смещение первой выбираемой записи, "R" - количество выбираемых записей. Проблема состоит в том, что если "O" = 9000, то перед тем как MySQL выберет 9001 запись, он пройдётся по первым 9000. Если "R" = 1000, то в общей сложности в выборке «примет участие» 10000 записей.
MySQL select limit может работать с начала таблицы или с её конца, в зависимости от направления сортировки записей asc / desc. Вариант работы с конца таблицы не является перспективным решением, хотя в некоторых ситуациях без него трудно обойтись.
Конструкция, где большое значение "R" мало будет интересовать разработчика и пользователя: MySQL delete limit. И то далеко не во всех случаях. В этой конструкции основной груз ответственности ложится на условие выборки (where) удаляемых записей.
В целях безопасности и контроля за процессом удаления записей разработчик обычно, заинтересован в использовании механизма AJAX и удаления записей небольшими порциями. При таком механизме посетитель сайта не заметит задержки в работе конструкции delete.
Выборка одной уникальной записи
 Вам будет интересно:Выбор уникальных записей в запросе MySQL: select distinct
Вам будет интересно:Выбор уникальных записей в запросе MySQL: select distinct
Правильное условие where и запрос "limit 1" MySQL выполнит моментально. Но удалять или выбирать по одной записи - далеко не всегда хорошее решение. Обычно порционная выборка по всем записям таблицы используется для страничной организации данных (например, комментарии, статьи, отзывы о товарах).
Решение о формировании содержимого веб-страницы должно быть принято моментально, но при классическом использовании MySQL limit O, R быстро будет выбран только первый десяток первой сотни записей, потом начнутся задержки.
Между тем не все так сложно, можно выбирать быстро по одной записи, но выигрывать за счёт дизайна и логики вывода записи в браузер посетителя.

Ничто не мешает сделать это эффектно и скрыть фатальные задержки времени за диалогом формирования контента.
Реляционные отношения в MySQL
MySQL - отличный инструмент для представления и обработки информации. Разработчик имеет в своём распоряжении качественный диалект языка SQL и удобный механизм формирования запросов. Ошибки и непредвиденные ситуации протоколируются, доступ к данным администрируется вплоть до уровня базовых операций.
Все недостатки относятся к самой концепции реляционных отношений. Что делать, эта концепция настолько фундаментально и надёжно работает, что ничего не остаётся, как считаться с её особенностями и учитывать их.
Современный уровень развития аппаратного обеспечения, качественная реализация функционала по всем инструментам MySQL (limit - не исключение) обеспечивают доступность больших объёмов данных при высоких скоростях работы и, самое важное, выборки.
Большие объемы и стандартный кэш
Буферизация данных перед записью и после выборки - идея прекрасная, ведущая свое начало из далеких 80-х годов. Кэширование стало модным на всех уровнях обработки данных от процессорного, сетевого, до, естественно, уровня http-сервера и собственно баз данных.
Разработчик может обратиться к администратору сервера или самостоятельно настроить кэширование на уровне Apache и MySQL или другой используемой комбинации программных средств, обеспечивающих функционирование веб-ресурса и сервера MySQL.
Это нормальное, стандартное решение. В большинстве случаев так принято поступать. В программировании достаточно давно востребована идея разделения труда. Разработчик делает сайты, администратор управляет работой всего, что обеспечивает оптимизацию использования сайта.
 Вам будет интересно:Ввод и вывод в Python. Input и print
Вам будет интересно:Ввод и вывод в Python. Input и print
В критичных ситуациях, когда таблицы базы данных велики, приходится отходить от принятых канонов. Нужно что-то менять в организации данных.
Табличная постраничная организация
Разработчики привыкли: реляционная база данных - это совокупность таблиц, взаимосвязанных друг с другом по ключам. Такая простая идея, как таблица, представленная массой однотипных страниц с одним именем, но разными индексами, выходит за пределы привычного представления.
Но что здесь странного? Таблица - это множество записей, содержащих различные данные, согласно типам полей (колонкам, шапке таблицы). Запрос MySQL query limit обращается к таблице "big_info" и выбирает c 100000 позиции 24 строки для отображения в браузере.
В таком решении в выборке участвует 100024 строки - это долго. Но если изменить ситуацию и всю таблицу "big_info" расписать на несколько сотен таблиц "big_info[0...999]" по 1000 записей, то проблема возникнет только при запросе MySQL "order by * limit O, R", поскольку сортировка будет крайне затруднена.
Впрочем, не только сортировка, но и любая другая операция над всеми записями невозможна средствами базы данных над таблицей, которая представлена несколькими таблицами. Индекс в таком контексте в MySQL отсутствует.
Реляционные отношения предполагают чёткость: есть база, в ней есть таблицы, в таблицах - колонки и записи. Ну ещё есть "примочки": хранимые процедуры, триггеры, условия и прочие детали.
Собственный кэш и понятие актуальности
Хороша идея «Яндекса» - «тепловизор»: тепловая карта кликов веб-страниц. Этот инструмент показывает в спектральном цветовом решении распространение актуальности интереса посетителей по «территории» страницы. Судя по всему, скоро появится новый школьный предмет - география веб-страницы: где и что размещать. Хорошее дополнение к общей географии...
Эта идея, переложенная на территорию записей большой таблицы базы данных, позволяет сформулировать объективный тезис: не вся территория записей востребована и не всегда.

Чем больше поток посетителей, тем больше закономерности к потребностям выборки. MySQL limit всегда выполняется точно и всегда по конкретной причине. Собрать конкретные причины никогда не составит труда. Привязать к каждой конкретной причине результаты MySQL limit в каждом конкретном случае - тривиальная задача.
Получается не постраничная организация таблицы в формате сотен однотипных страниц, а конус востребованности информации. Только в фатальных случаях или при заходе на страницу информационно ёмкого посетителя происходит выборка большого объёма данных. В обычном режиме - выбираются крохи.
Собственный кэш элементарно решает проблему скорости: выборка идёт по ключу «конкретная причина» из маленькой таблицы результатов последних операций выборки из одной большой таблицы.
Сортировки и другие оптовые операции
Проблема больших объёмов данных упирается в производительность аппаратно-программного обеспечения. Сегодня достигнут потрясающий уровень производительности, но объёмы данных тоже резко возросли.
Когда растёт скорость и качество дорог, адекватно растёт потребность в быстром перемещении и моментальном решении задач.
Простая операция сортировки, добавления записи или поиска данных, затрагивающая прямо или косвенно все записи большой таблицы, - потенциальный тормоз, гарантированная потеря производительности.

Реляционные отношения слишком долго владели пальмой первенства, но уступать дорогу по сей день не намерены: попросту некому. Других вариантов организации данных, которые обеспечивают моментальную навигацию по большим объёмам информации, не придумал даже сверхлидер отрасли «Большая информация» - Oracle. Но Oracle обеспечил хороший опыт и отличные знания в реализации SQL-языка и его диалектов. На функционал MySQL это наложило конкретный отпечаток качества.
Разработчик может смело использовать конструкцию MySQL limit на одной таблице данных и иметь свободный доступ к оптовым операциям над этой большой таблицей.
Естественное восприятие информации
Человек воспринимает и обрабатывает, в большей части бессознательно, огромные объёмы информации, которые недоступны самым совершенным инструментам от Oracle. Но он может не особенно гордиться этим. Oracle может делать миграции таких объёмов данных и выполнять такие сортировки, для исполнения которых потребуется не одна человеческая жизнь и не в одной сотне экземпляров.

Каждый должен заниматься своим делом и делать это дело максимально эффективным образом. Реляционные отношения никогда не отомрут - они свойственны данным, это их неотъемлемая составляющая. Но в реализации баз данных у реляционных отношений не хватает семантики. Ключевая организация, индексы для доступа к записям - это не тот смысл, который обеспечивает быстрый доступ к информации.
Последовательная организация памяти машин и эмуляция ассоциативного доступа к информации - реальная причина потери времени при доступе к большой таблице для выборки части информации при соблюдении её целостности для выполнения групповых операций.
Информационные объекты и естественные ассоциации
Избежать последовательности в исполнении операций разработчик пока не может. Так устроен компьютерный мир. Компьютер имеет один процессор, а многоядерные и многопроцессорные варианты - это всё же не нейронная организация параллельной обработки информации, которую использует человеческое мышление.
Разработка алгоритма всегда апеллирует к одному процессу, хоть и разбиваемому на множество потоков. Программирование пока идёт на одном уровне, даже когда код построен в формате системы взаимодействующих объектов, экземпляры которых функционируют сами по себе.
Вопрос уже не столько в качестве строения информационных систем в виде самостоятельных объектов, сколько в среде, которая обеспечивает их функционирование. Среда - последовательна, а не параллельна.
Рост количества ядер и количества процессоров в одном компьютере, планшете или ином девайсе не делает их ассоциативными вычислительными устройствами.
Но выход всё же есть: каждое конкретное применение - это вопрос, на который нужно найти быстрый ответ. Нужно сделать быстрый выбор (MySQL limit) при том, что остальной функционал (MySQL order by, group by, join & where) не пострадает, таблица не будет разбиваться на множество однотипных частей, а в процедуры кэширования будут попадать обновлённые данные сразу после их обновления, а не тогда, когда на них поступит очередная «конкретная причина».
Язык SQL - это хороший язык, но если к нему добавить ассоциации, он станет ещё лучше.